Chapter 1
4 Components : CPU Main Memory I/O Modules System Bus
OS
•Exploits the hardware resources of one or more processors
•Provides a set of services to system users
•Manages secondary memory and I/O devices
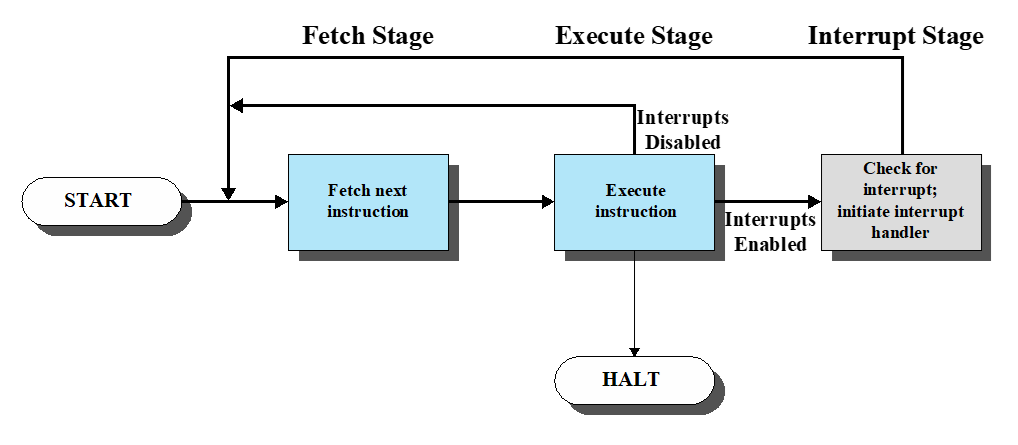
Interrupt
Processor waits for IO device may cause waste use of processor
Class of Interrupts
- Program: Generated by some condition that occurs as a result of an instruction execution, such as arithmetic overflow, division by zero…
- Timer: Generated by a timer within the processor
- I/O
- Hardware failure: such as power failure or memory parity error.
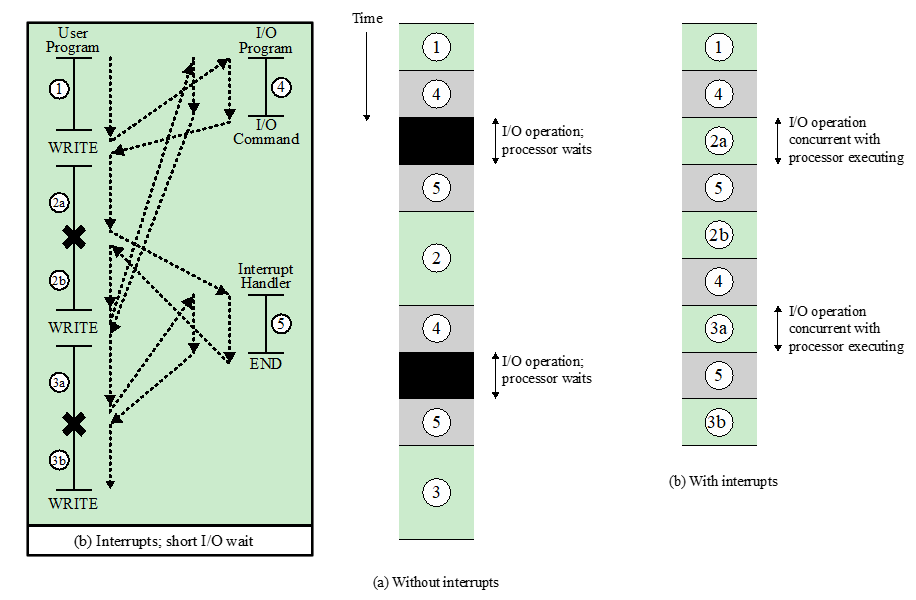
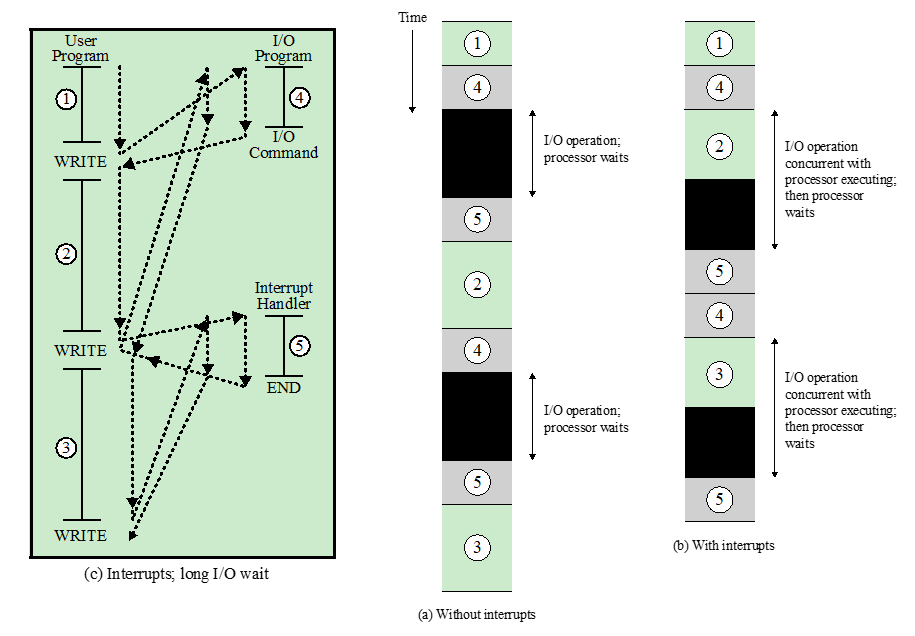
Short I/O wait & Long I/O wait
Short I/O wait
4的等待时间比较短, 不够执行完2
Long I/O wait
4的等待时间比较长,执行完2之后还在等
Multiple Interrupts

中断执行的程序更重要 例如 Y>X>User Program
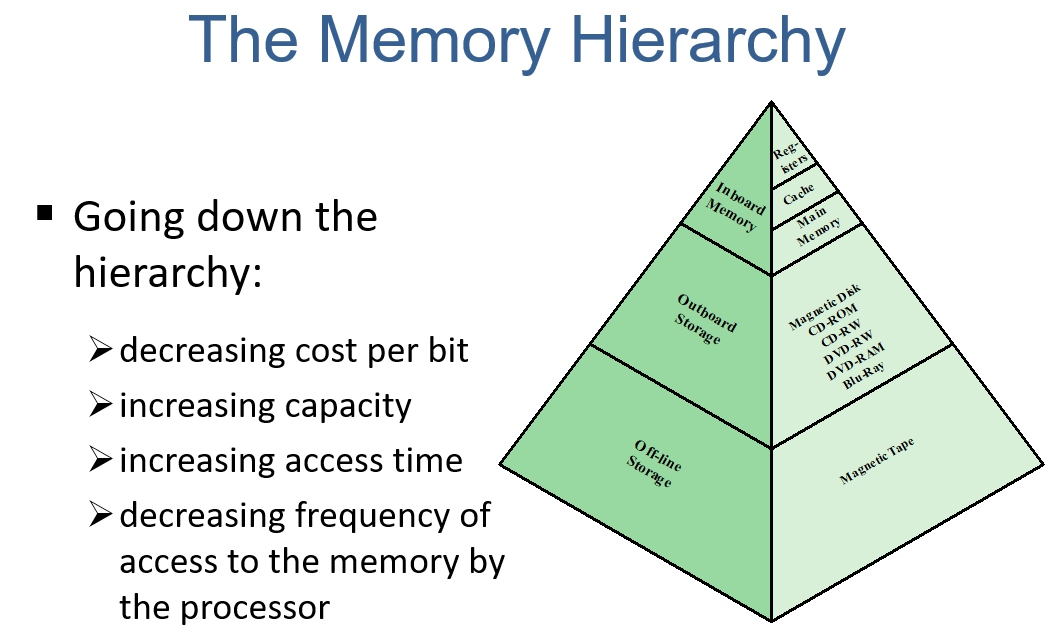
Memory Hierarchy
Major constraint
- amount
- speed
- expense
Principle of Locality & Memory
Locality(局部性原理)
•Memory references by the processor tend to cluster
CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
Over a long period of time, the clusters in use change, but over a short period of time, the processor is primarily working with fixed clusters of memory references.
Memory Hierarchy
Data is organized so that the percentage of accesses to each successively(依次) lower level is substantially(显著) less than that of the level above
Let level 2 memory contain all program instructions and data. The current clusters can be temporarily placed in level 1. From time to time, one of the clusters in level 1 will have to be swapped back to level 2 to make room for a new cluster coming in to level 1.
Cache Memory
Cache principles
- Invisible to OS
- Interacts with other memory management hardware
- Processor must access memory at least once per instruction cycle
- Processor execution is limited by memory cycle time
Cache Motivation
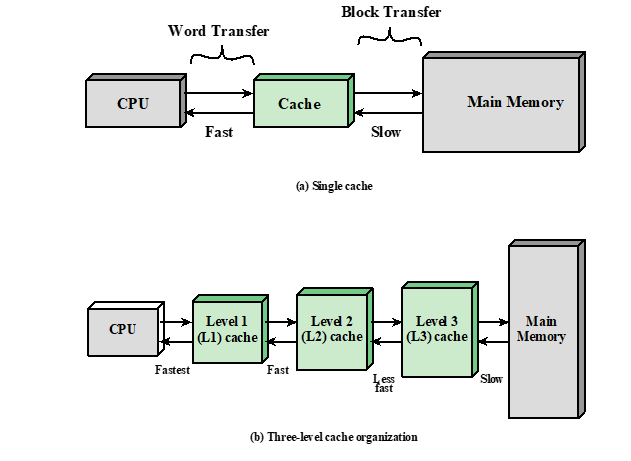
Cache中复制了一部分memory中的数据,当CPU想读数据时,先从cache里面找,如果没有,cache从main memory中读取相应的数据,然后再返回给processor,因为局部性原理,当 a block of data 被取到cache时,许多near future会用到的数据也会在这个block里
Cache Design
Cache and block size
cache size: cache可以缓存最大数据的大小
small caches can have a significant impact on performance
block size: the unit of data exchanged between cache and main memory
As block size increases, hit ratio 先上升(the principle of locality:被引用词附近的数据很可能在不久的将来被引用的可能性很高) 然后下降 (as the block becomes even bigger and the probability of using the newly fetched data becomes less than the probability of reusing the data that have to be moved out of the cache to make room for the new block.)
Mapping Function
Two constraints
-
when one block is read in, another may have to be replaced
尽量减少替换我们不久将需要的区块的可能性
-
the more flexible the mapping function,
- the more complex is the circuitry required to search the cache
- the more scope we have to design a replacement algorithm to maximize the hit ratio
Replacement Algorithms
-
FIFO
-
Least Recently Used (LRU) Algorithm
replace a block that has been in the cache the longest with no references to it(Hardware mechanisms(硬件机制) are needed to identify the least-recently-used block)
I/O techniques
当处理器遇到与I/O有关的指令时,它会通过向适当的I/O模块发出命令来执行该指令
Programmed I/O
the I/O module performs the requested action and then sets the appropriate bits in the I/O status register but takes no further action to alert the processor.
它不会中断处理器。因此,在调用I / O指令之后,处理器会定期检查I / O模块的状态,直到发现操作已完成。
As a result, the performance level of the entire system is severely degraded.
Interrupt-Driven I/O
(如上面说的interrupt的例子)
drawback
- The I/O transfer rate is limited by the speed with which the processor can test and service a device.
- 每次I/O transfer都必须执行许多指令
Direct Memory Access(DMA)
🍶 When large volumes of data are to be moved
The DMA function can be performed by a separate module on the system bus or it can be incorporated into an I/O module.
processor issues a command to the DMA module containing:
•whether a read or write is requested
•the address of the I/O device involved
•the starting location in memory to read/write
•the number of words to be read/written
- Transfers the entire block of data directly to and from memory without going through the processor
- 处理器将这个IO操作委托给DMA模块之后,继续其他工作。DMA模块将整个数据块(一次一个字)直接传输到或从内存中,而不需要经过处理器。当传输完成时,DMA模块向处理器发送一个中断信号。因此,处理器只在传输的开始和结束时涉及。
- 当需要处理器访问总线时,在DMA传输期间处理器执行得更慢。然而,对于多字I/O传输,DMA远比interrupt-driven或programmed I/O更有效。
Multiprocessor and multicore organization
Symmetric multiprocessors
-
有两个或更多具有类似能力的类似处理器。
-
这些处理器共享相同的main memory和I/O facility,并通过bus或其他内部连接方案相互连接,这样每个处理器的memory access time大致相同。
-
所有处理器都共享对I/O设备的访问,要么通过相同的通道,要么通过为相同设备提供路径的不同通道。
-
所有处理器都可以执行相同的功能(因此有了对称这个术语)。
-
该系统由一个集成的操作系统控制,该操作系统在作业、任务、文件和程序之间提供交互数据元素的水平。
advantages
- Performance: if work can be done in parallel
- Availability: the failure of a single processor does not halt the machine
- Incremental growth: an additional processor can be added to enhance performance
- Scaling: vendors(供应商) can offer a range of products with different price and performance characteristics
Multicore computers
Designers have found that the best way to improve performance to take advantage of advances in hardware is to put multiple processors and a substantial amount of cache memory on a single chip.



